Hi All,
This Blog is all about the various challenges and tasks we perform while coding.It will cover various updates related to Spring,Struts,Hibernate,JPA,Web Services,Javascript, Bootstrap,third party integration etc
POSTMAN provides many features for clubbing ,testing and running API through it. There are many features which can be handy while testing or developing REST APIs.
Pre-Request-Script feature is one the core feature which can be used for setting Token for subsequent request. We can make use of environment variable and set same in header in a collection.
1)minikube start --vm-driver=hyperkit : Will start one node cluster on virtual machine.
2)minikube status : toc check the status of the cluster.
Note: Minikube is just for starting and deleting the cluster specific stuff whereas kubectl is another client which is basically used to interact with cluster and used to perform different task like create deployment etc.
3)kubectl get pod: to list the pods created.
4)kubectl get services: list all the created servces.
5)kubectl get nodes: list all the nodes in clsuter.
6)kubectl create deployment deploymnet1 --image=nginx : create deployment for nginx image wherein the image will be pulled from docker hub.
7)kubectl get deployment :: will list the deployment details.
8)kubectl get replicaset:: will list how many replica set are created for each deployment .
9)kubectl edit deployment :: to edit deployment file.
Kubernetes is a container orchestration framework built by Google.
k8s
abbreviation for kubernetes ("ubernete" is 8 letters)
Openshift
Openshift is an application Platform-as-a-Service built by Red Hat to extend kubernetes.
Origin
Openshift Origin is the open source base for Openshift installations. Red Hat sells both a cloud (Openshift Online) and on-prem (Openshift Container Platform) offering. Because Origin is open source, it can be installed an managed freely.
Object
Objects
In this context, an object refers to a k8sobject. The definition for an Openshift Object is the same; Openshift extends the k8s API with additional objects.
S2I
Source-to-Image
S2I is a way of building docker images. Though built for the Openshift project, it can be run fully independently, though naturally Openshift has special support for it. The chief benefit of S2I is not having to define a Dockerfile for each application, which implicitly means that there is a standard build methodology per programming language.
Helm is a CLI tool for working with K8s or Openshift Objects (usually yaml files). It is extensively documented.
Tiller
Tiller is a GRPC server component of the Helm project. The Helm CLI sends requests to Tiller for almost all of its operations, such as running an installation.
Chart
A Chart is a "package" in the Helm world. It contains one or more templated k8s objects. Charts are versioned and published to a Chart Repository.
Chart Repository
Generally, a Chart Repository is a static file server with tarballs of Charts. We can use github pages as its chart repository, and any charts committed to master on your GitHub repo can be automatically published.
Motor
Motor is a RESTful interface for Tiller. In addition to translating rest calls to GRPC, Motor also handles RBAC for installs and release data.
1)oc login clusterURL : used to connect to cluster.
2)oc project projectName : used to select project that need to be used.
3)oc get pods : to get pod details.
4)oc get dc : to get deployment configs detail.
5)oc get rc : to get replication controller details.
6)oc get services : to get services details.
7)oc get routes : to get route details.
8)oc scale --replicas=2 podname : to scale replicas to 2 and this will ensure that always there are 2 instances running with auto healing capability which means in case any instance goes down then it will try to bring instance up automatically.
9)oc policy : to provide access to. different users and groups.
10)oc rsh podname : take remote session of POD for debugging and inspecting.Though pod or a container is immutable. but we can take remote session and check in case there is any issue in POD .
S3 stands for Simple Storage Service and essentially it's object storage in the cloud. It provides secure, durable, and highly scalable object storage. It allows you to store and retrieve any amount of data from anywhere on the web at a very low cost. So it's extremely scalable.And the other cool thing about S3 is it's really, really simple to use.
S3 is object-based storage, and basically it manages data as objects rather than in file systems or data blocks.So you can upload any file type that you can think of to S3 like like image files, text files,videos, web pages etc. But one important point is that you can only store static content on S3 which means you cannot store any dynamic content for now like installing an OS etc.
The total volume of data and the number of objects you can store is unlimited in S3 and the maximum object size can be upto 5 TB as of today.
Where do we store our file in S3?
We store our files in a thing called a bucket. S3 bucket is basically a folder inside S3. Important thing to know is that S3 bucket name is universal namespace and all AWS accounts share S3 bucket name globally which means each bucket name shall be globally unique on every creation.
What happens when bucket is created?
let' say you created bucket by the name of s3bucket , you will see that the new URL will be generated like below
https://{name of bucket}.s3.{region where bucket belongs to}.amazonaws.com/{key name means object which will get persisted like file etc}
We can also have versioning with S3 bucket which could be good option for daily monitoring and tracking.
Some of the objects associated with S3 are
i) key
ii)Value
iii)Version Id
iv)metadata
When bucket is created by default bucket is private and in case you want to make objects public then make sure bucket need to be made public first .
General Response Codes
when you upload a file to S3, if that upload is successful, your browser will receive a HTTP 200 code. There shall be many other response code which you can discover from the AWS doc or I will also try to update those later.
How safe and durable is data stored in S3?
So just remember S3 is a safe place to store your files.The data is always spread across multiple devices and facilities in order to ensure availability and durability.So it's not just in a single data center in a single server.It's always spread across multiple devices and multiple facilities.It can be across multiple Availability Zones and this all is done to ensure availability and durability.
How data can be secured in S3?
Data can be secured by enabling 3 ways.
1) Enabling Server side encryption : Whenever new objects gets created all the new objects shall be encrypted by default.
2) Enabling Access control List (ACLs) : Specify what accounts and groups are allowed to access specific objects in a bucket.
3) Enabling Bucket Policies : What operations are allowed in a bucket. Like PUT is allowed by DELETE is not allowed.
Difference between ACLs and Bucket policies:
ACLs are applied at individual object level in or inside bucket whereas bucket policies are applied at bucket level.
Data consistency model in S3?
S3 supports strongly READ-after-Write consistency model in which after every update new read will show all new changes immediately.
Also strong consistency for list operation wherein we can see list showing all the latest write updates.
Jenkins being one of the most popular CI/CD tool across the globe but there is still way to figure out credentials stored in it.
It has a lot of incredible features that make life easier. One of the most powerful feature, is Script Console. Jenkins offers aconsole that can execute Groovy scripts to do anything within the Jenkins master run-time or in the run-time on agents.
This console can be used in configuring Jenkins and debugging Jenkins run-time issues, misusing this console with leak of security may cause a lot of harm to you. You may lose the server or even get your infrastructure hacked.
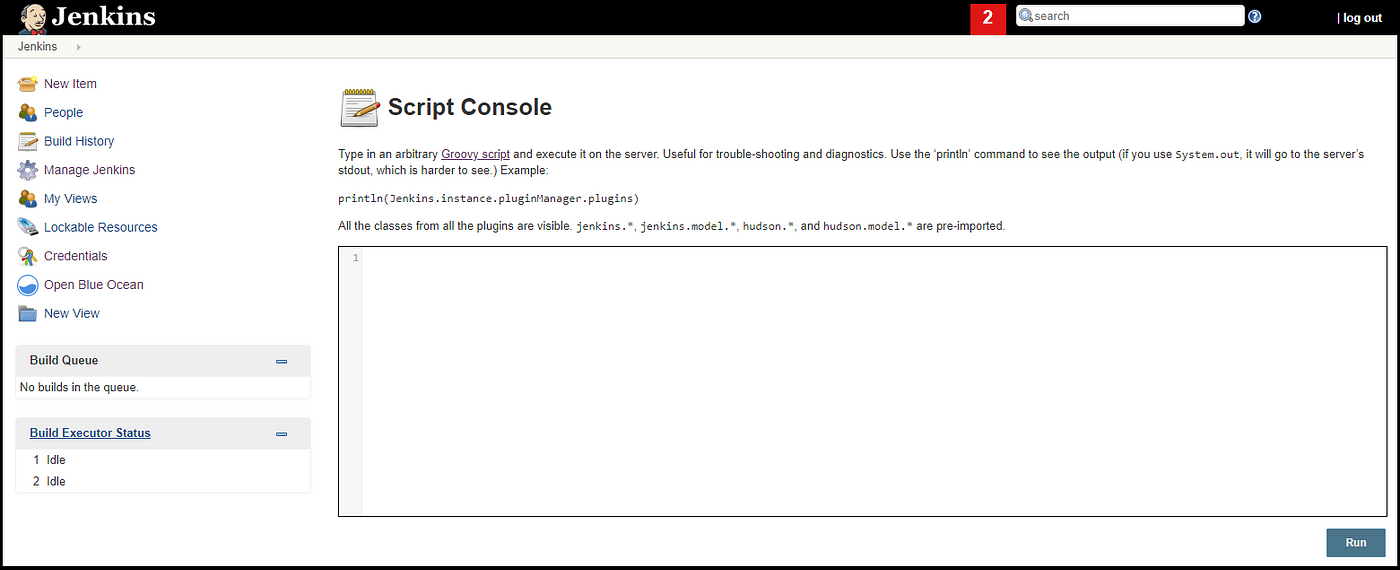
Access Script Console:
Go to “Manage Jenkins” then click “Script Console”. Or you can easily go to this URL, “Jenkins_URL/script”.
Type any groovy code in the box then click Run. It will be executed on the server.
Examples of what can be done:
You can disable all jobs, delete the work-space for all disabled jobs to save space, decrypt credentials configured within Jenkins and decrypt any password stored in Jenkins for instance, “user password” if you have its hash code.
To disable all jobs:
To disable all jobs in your Jenkins at once, go to the magic console and execute the next peace of code.
import hudson.model.*
disableChildren(Hudson.instance.items)
def disableChildren(items) { for (item in items) { if (item.class.canonicalName == 'com.cloudbees.hudson.plugins.folder.Folder') { disableChildren(((com.cloudbees.hudson.plugins.folder.Folder) item).getItems()) } else { item.disabled=true item.save() println(item.name) } } }
You can even delete their work-space after being disabled:
Decrypt credentials defined in Jenkins and list values.
Credentials are very critical and it’s important to save them in some place that no one can get them easily. Saving them in Jenkins is not the best way to do so.
The next set of code can easily print out all credentials stored in Jenkins server of type Private-Key then of type Username and Password with their VALUES!.
Accounts’ password and proxy user password are hashed and saved some where on the server. Assuming that you got that hash, then you can decrypt it using the next code.
println(hudson.util.Secret.decrypt("{HASHxxxxx=}"))# or /////println(hudson.util.Secret.fromString("{HASHxxxxx=}").getPlainText())
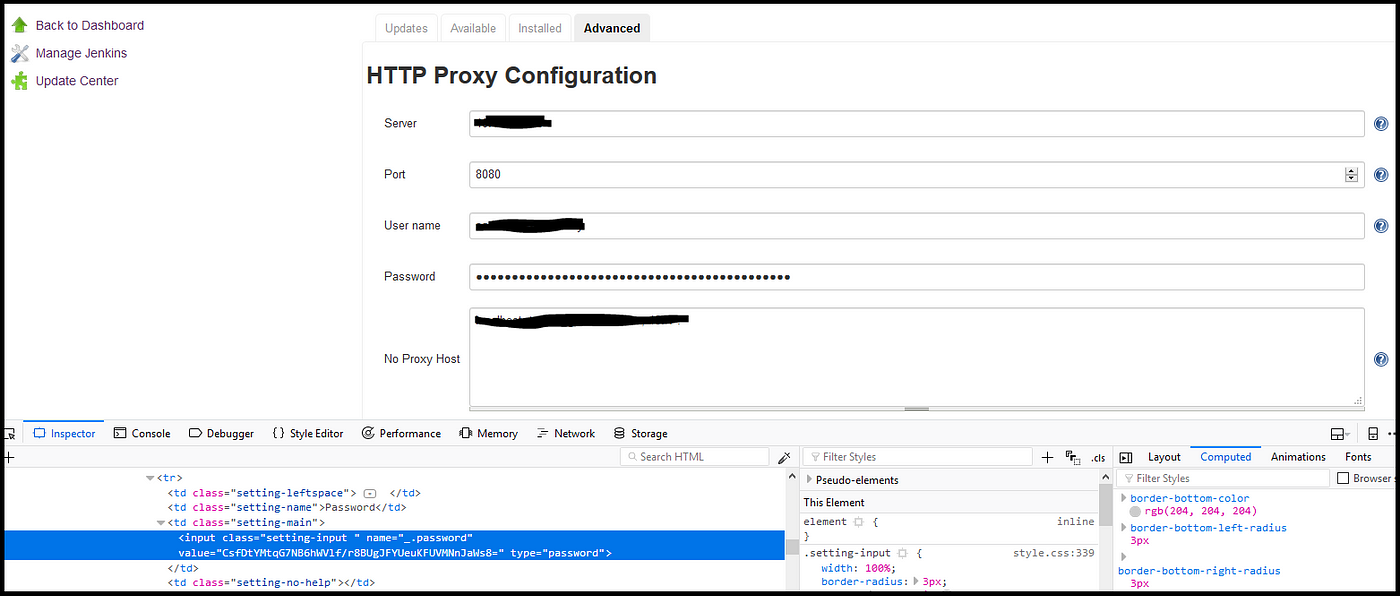
Of course, getting the hash is difficult but here is an example of how easy it might be.
On a server, a proxy is defined and username/password are saved to use this proxy. If you inspected the password field you will get the hashed value of the password from HTML!
Jenkins saves passwords value and return the hash to the browser to use it later.
Running shell commands:
As a debugging tool, the console gives you the ability to run any shell command. i.e. to execute the commend “ls” on the server:
println new ProcessBuilder('sh','-c','ls').redirectErrorStream(true).start().text
You can run any shell commands or scripts on the server by creating a job and execute you commands. But you can use the console as a hidden place to do what ever you want to do without letting others know about it.